Collinear is building the Simulation Lab: an interactive playground where agents learn new skills and improve existing capabilities. We simulate thousands of real-world users, tools, and workflows — so your agents can fail, learn, and improve before they ever touch production. Collinear provides isolated, reproducible playgrounds populated with realistic simulated applications, generates tasks and automated verifiers, and produces grounded reward signals by running agents through multiple attempts per task. The result is a continuous loop: evaluate agent behavior, identify gaps, and iterate — all before deploying to real users.Documentation Index
Fetch the complete documentation index at: https://docs.collinear.ai/llms.txt
Use this file to discover all available pages before exploring further.
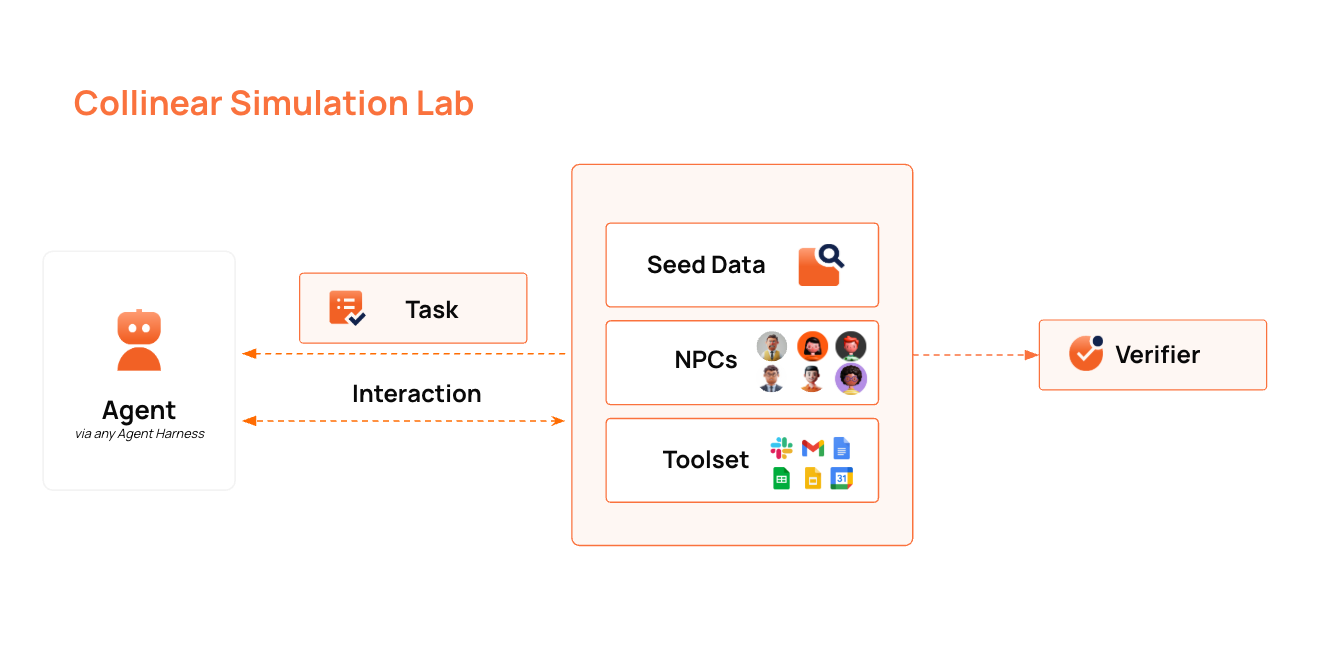
Why use a Simulation Lab?
Without a Simulation Lab:- Little to no control on agent environment: You’re testing against live or mock systems that don’t reflect real-world complexity.
- Hard to reproduce or predict outcomes: Flaky results make it difficult to pinpoint what went wrong or why.
- Static signal and rewards: Evaluation criteria are fixed and can’t adapt to evolving agent capabilities.
- Fully controlled behavior and actions: Every tool, user, and workflow runs in an isolated, deterministic playground you configure.
- Reproducible and predictable outcomes: Run the same scenario thousands of times with clean state to get statistically meaningful results.
- Dynamic signal and rewards: Verifiers and reward functions evolve alongside your agent, giving you grounded feedback at every iteration.
Features
Scalability
IMPALA system design so GPUs stay saturated during async rollouts
Fidelity
Train and evaluate on realistic world interactions
Adaptability
Dynamically compose scenarios, tasks, and verifiers
Use Cases
Surface failure modes early
Discover real-world failures before they reach production
Close the loop
Hill-climb on existing capabilities through iterative evaluation
Expand to new capabilities
Extend your agent into new domains and skill sets